2.7. Maintenance use case¶
A consumer of the NFVI wants to interact with NFVI maintenance, upgrade, scaling and to have graceful retirement. Receiving notifications over these NFVI events and responding to those within given time window, consumer can guarantee zero downtime to his service.
The maintenance use case adds the Doctor platform an admin tool and an
app manager component. Overview of maintenance components can be seen in
figure-p2.
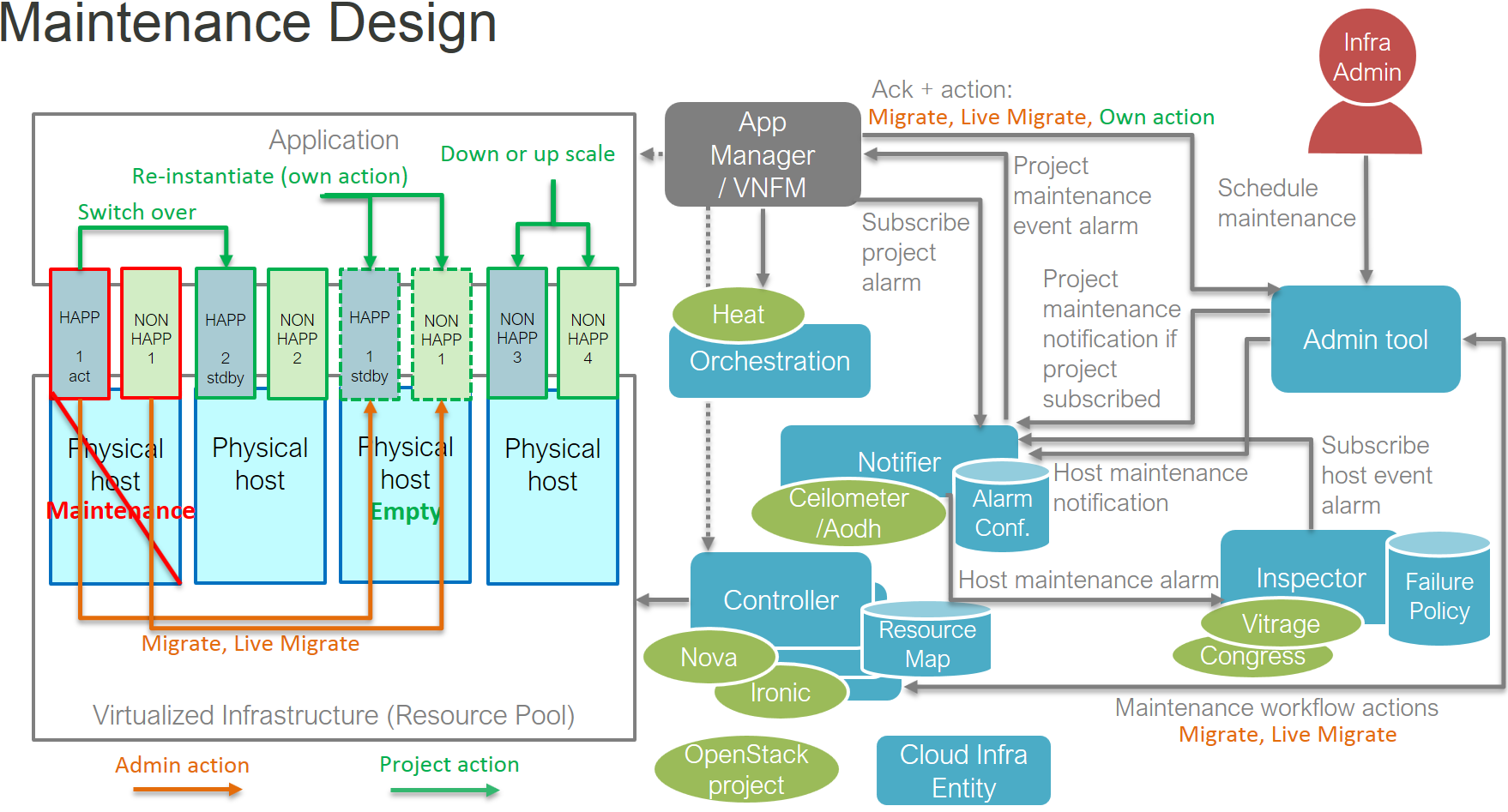
Doctor platform components in maintenance use case¶
In maintenance use case, app manager (VNFM) will subscribe to maintenance notifications triggered by project specific alarms through AODH. This is the way it gets to know different NFVI maintenance, upgrade and scaling operations that effect to its instances. The app manager can do actions depicted in green color or tell admin tool to do admin actions depicted in orange color
Any infrastructure component like Inspector can subscribe to maintenance notifications triggered by host specific alarms through AODH. Subscribing to the notifications needs admin privileges and can tell when a host is out of use as in maintenance and when it is taken back to production.
2.8. Maintenance test case¶
Maintenance test case is currently running in our Apex CI and executed by tox.
This is because the special limitation mentioned below and also the fact we
currently have only sample implementation as a proof of concept and we also
support unofficial OpenStack project Fenix. Environment variable
TEST_CASE=’maintenance’ needs to be used when executing “doctor_tests/main.py”
and ADMIN_TOOL_TYPE=’fenix’ if want to test with Fenix instead of sample
implementation. Test case workflow can be seen in figure-p3.
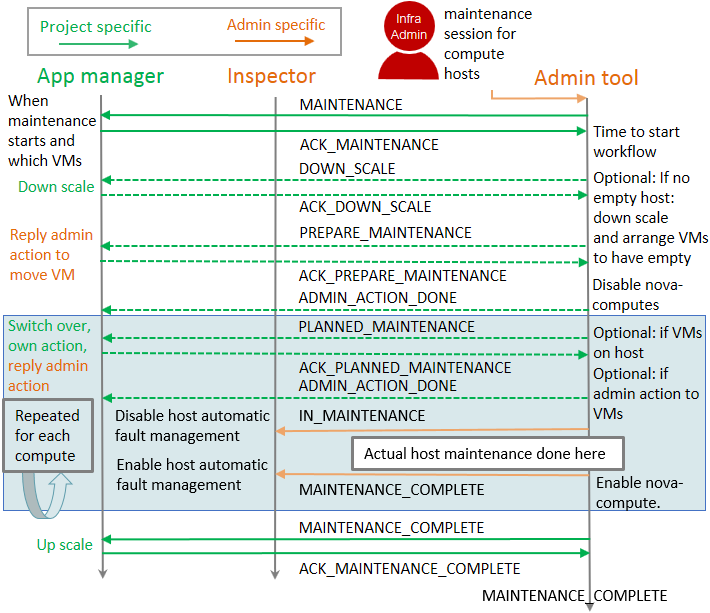
Maintenance test case workflow¶
In test case all compute capacity will be consumed with project (VNF) instances. For redundant services on instances and an empty compute needed for maintenance, test case will need at least 3 compute nodes in system. There will be 2 instances on each compute, so minimum number of VCPUs is also 2. Depending on how many compute nodes there is application will always have 2 redundant instances (ACT-STDBY) on different compute nodes and rest of the compute capacity will be filled with non-redundant instances.
For each project specific maintenance message there is a time window for app manager to make any needed action. This will guarantee zero down time for his service. All replies back are done by calling admin tool API given in the message.
The following steps are executed:
Infrastructure admin will call admin tool API to trigger maintenance for compute hosts having instances belonging to a VNF.
Project specific MAINTENANCE notification is triggered to tell app manager that his instances are going to hit by infrastructure maintenance at a specific point in time. app manager will call admin tool API to answer back ACK_MAINTENANCE.
When the time comes to start the actual maintenance workflow in admin tool, a DOWN_SCALE notification is triggered as there is no empty compute node for maintenance (or compute upgrade). Project receives corresponding alarm and scales down instances and call admin tool API to answer back ACK_DOWN_SCALE.
As it might happen instances are not scaled down (removed) from a single compute node, admin tool might need to figure out what compute node should be made empty first and send PREPARE_MAINTENANCE to project telling which instance needs to be migrated to have the needed empty compute. app manager makes sure he is ready to migrate instance and call admin tool API to answer back ACK_PREPARE_MAINTENANCE. admin tool will make the migration and answer ADMIN_ACTION_DONE, so app manager knows instance can be again used.
figure-p3 has next a light blue section of actions to be done for each
compute. However as we now have one empty compute, we will maintain/upgrade that
first. So on first round, we can straight put compute in maintenance and send
admin level host specific IN_MAINTENANCE message. This is caught by Inspector
to know host is down for maintenance. Inspector can now disable any automatic
fault management actions for the host as it can be down for a purpose. After
admin tool has completed maintenance/upgrade MAINTENANCE_COMPLETE message
is sent to tell host is back in production.
Next rounds we always have instances on compute, so we need to have PLANNED_MAINTANANCE message to tell that those instances are now going to hit by maintenance. When app manager now receives this message, he knows instances to be moved away from compute will now move to already maintained/upgraded host. In test case no upgrade is done on application side to upgrade instances according to new infrastructure capabilities, but this could be done here as this information is also passed in the message. This might be just upgrading some RPMs, but also totally re-instantiating instance with a new flavor. Now if application runs an active side of a redundant instance on this compute, a switch over will be done. After app manager is ready he will call admin tool API to answer back ACK_PLANNED_MAINTENANCE. In test case the answer is migrate, so admin tool will migrate instances and reply ADMIN_ACTION_DONE and then app manager knows instances can be again used. Then we are ready to make the actual maintenance as previously trough IN_MAINTENANCE and MAINTENANCE_COMPLETE steps.
After all computes are maintained, admin tool can send MAINTENANCE_COMPLETE to tell maintenance/upgrade is now complete. For app manager this means he can scale back to full capacity.
There is currently sample implementation on VNFM and test case. In infrastructure side there is sample implementation of ‘admin_tool’ and there is also support for the OpenStack Fenix that extends the use case to support ‘ETSI FEAT03’ for VNFM interaction and to optimize the whole infrastructure mainteannce and upgrade.